


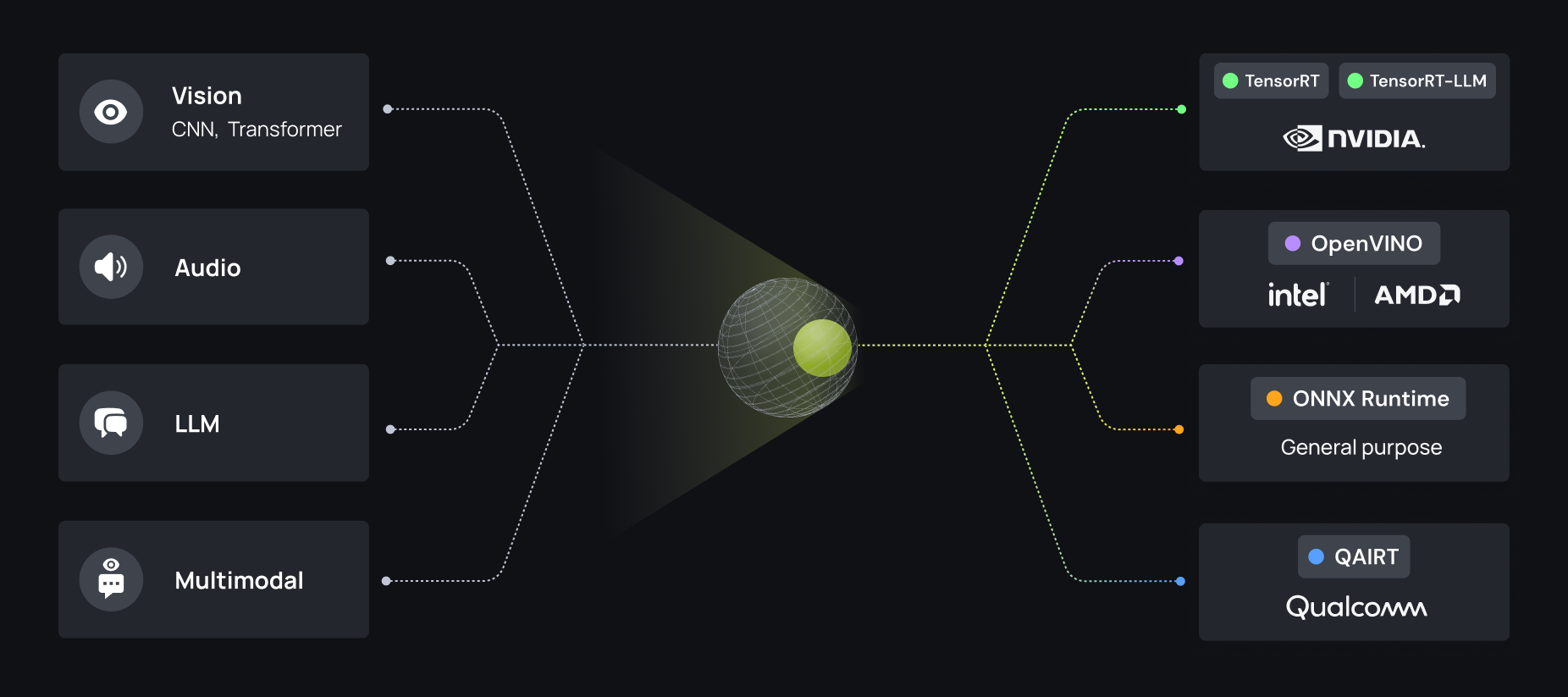
Vision

Audio

LLM
Reduce memory footprint
up to
Smaller Size
Enhance UX
up to
Faster Speed
Improve ROI
up to
Cost Saving
Keep it performant
up to
Accuracy Loss

Try out CLIKA pre-compressed Models
Go to Modelverse ->Try out CLIKA pre-compressed models— optimized for speed, size, and deployment flexibility.
Win more with efficient version of your AI
See ACE in action ->Unlock the full power of your AI with CLIKA’s efficient, hardware-optimized compression pipeline.
See synergy with your product? Let’s chat!
Contact Us ->Think there’s a fit with your product or platform? Let’s explore how we can work together.

