
Precision-Aware Compression
CLIKA's Automated Compression Engine (ACE) doesn't just shrink your model. It analyzes every layer, finds where precision can drop and where it can't, and builds a custom mixed-precision recipe (down to 1-bit where possible) tailored to your specific model and target hardware. The result: the smallest possible model that still performs.

Benefits
One compression pass gets you a model that runs faster, fits in less memory, and costs less to deploy at scale. The key difference: you don't sacrifice accuracy to get there. CLIKA finds the compression ceiling, not just a compression shortcut.

CLIKA x WEDA Workflow
CLIKA prepares the model. WEDA delivers it everywhere. Together, we close the gap between "model ready" and "running in production across every device."
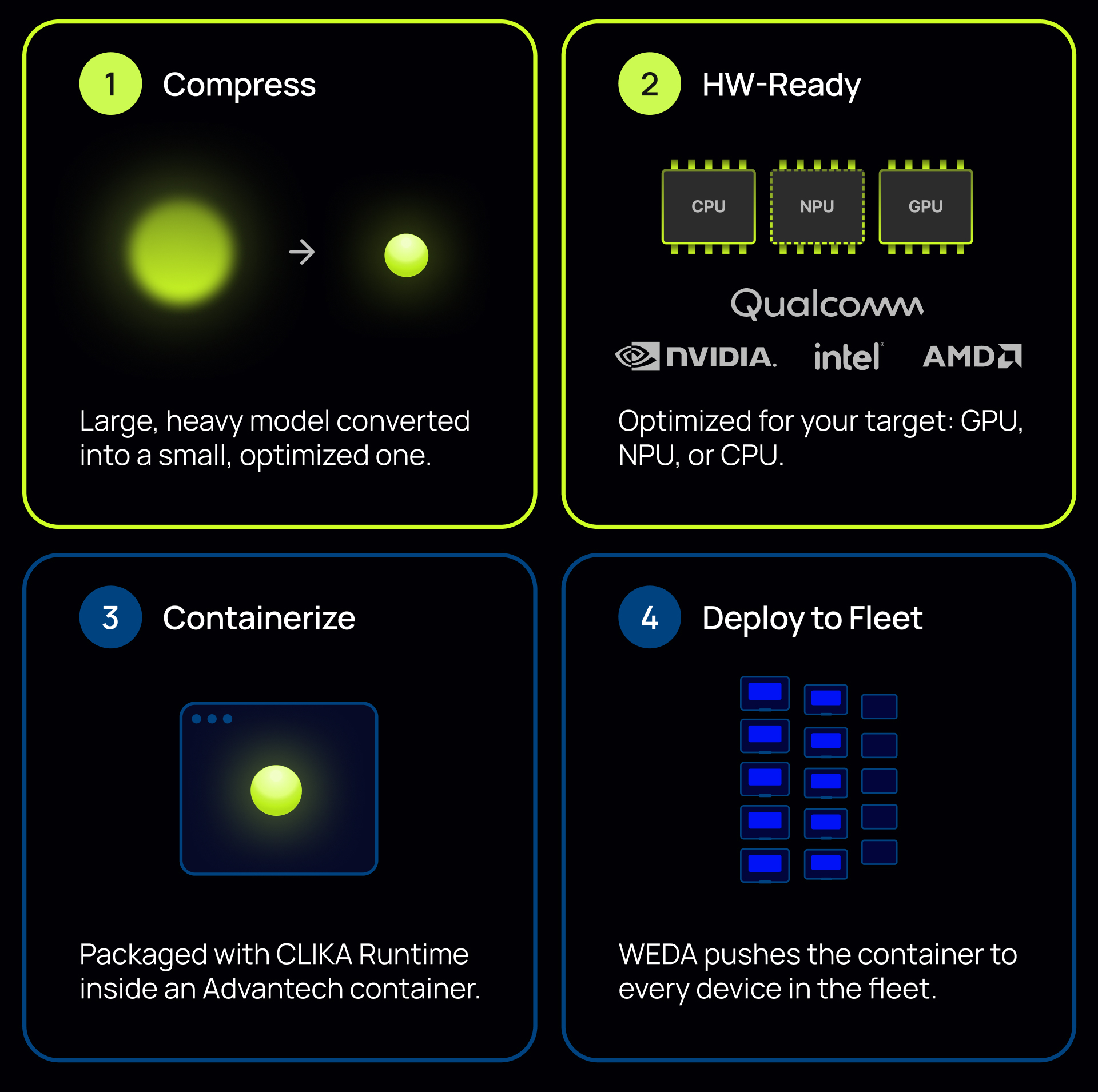
Before & After
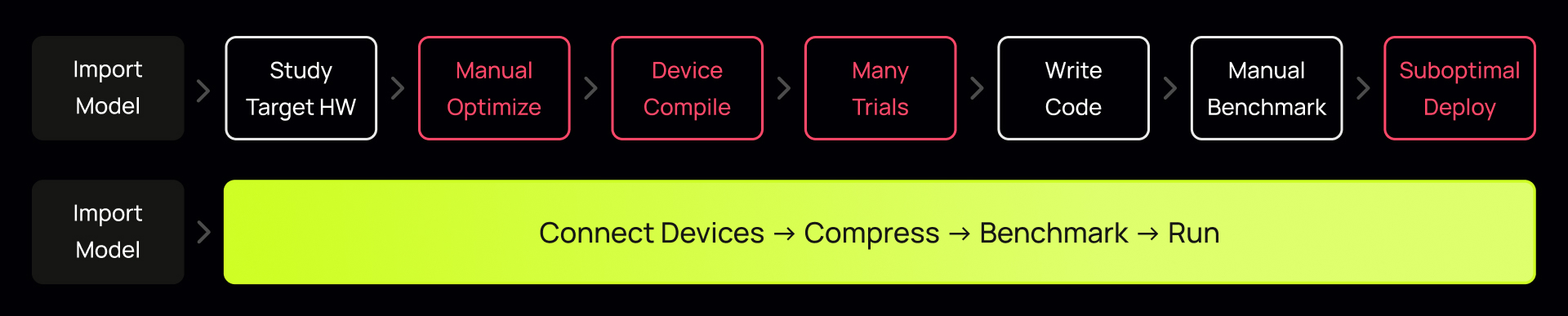
What used to take seven fragile steps full of errors and a team of engineers is now a single automated pipeline. No more guessing which optimizations work, no more rewriting code per chip, no more praying the benchmark holds in production.
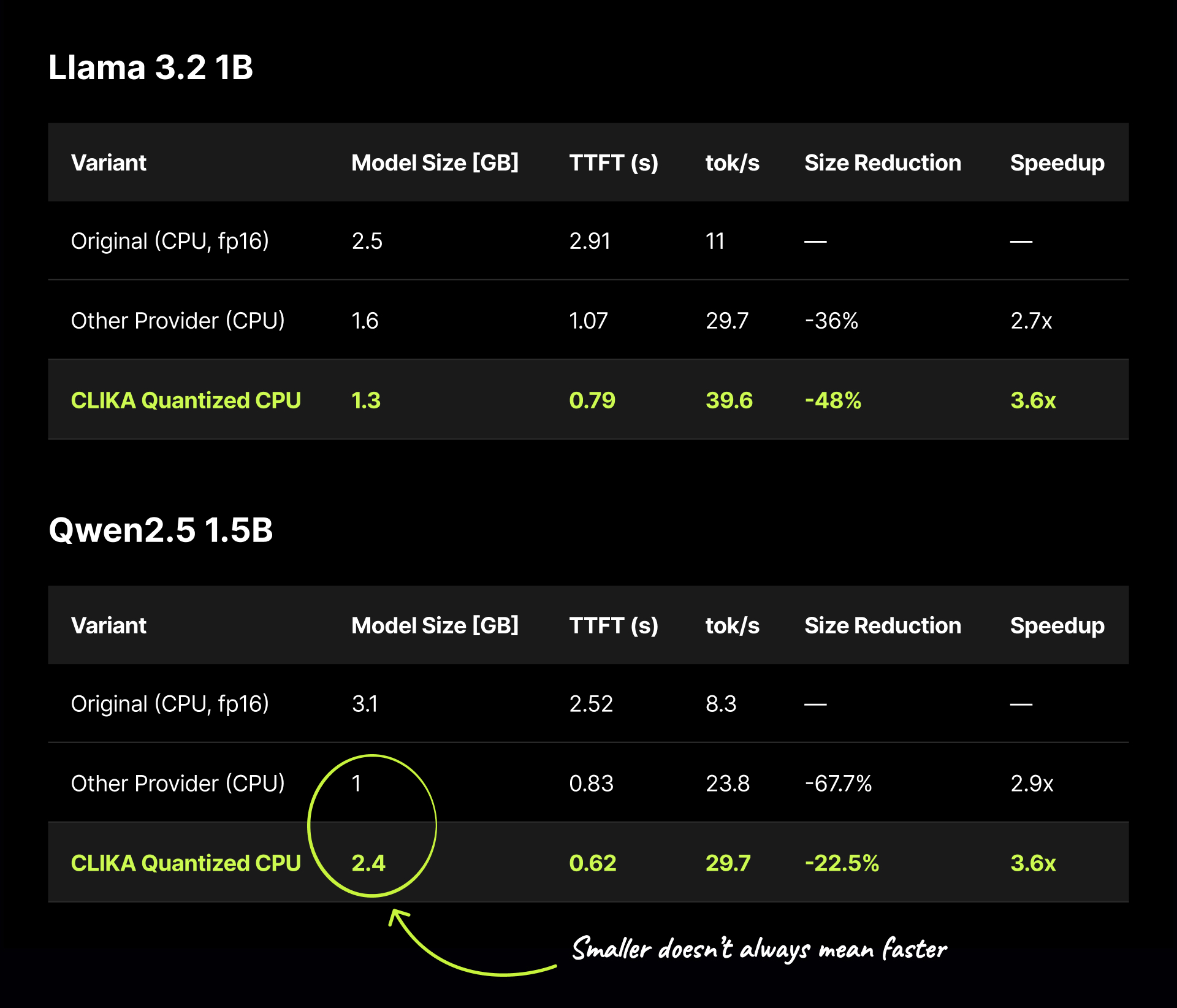
Benchmarks Seeing the final results before deep-dive
On Advantech’s AMD Ryzen 7 PRO 8845HS :
On Advantech’s QCS6490 Qualcomm Board:
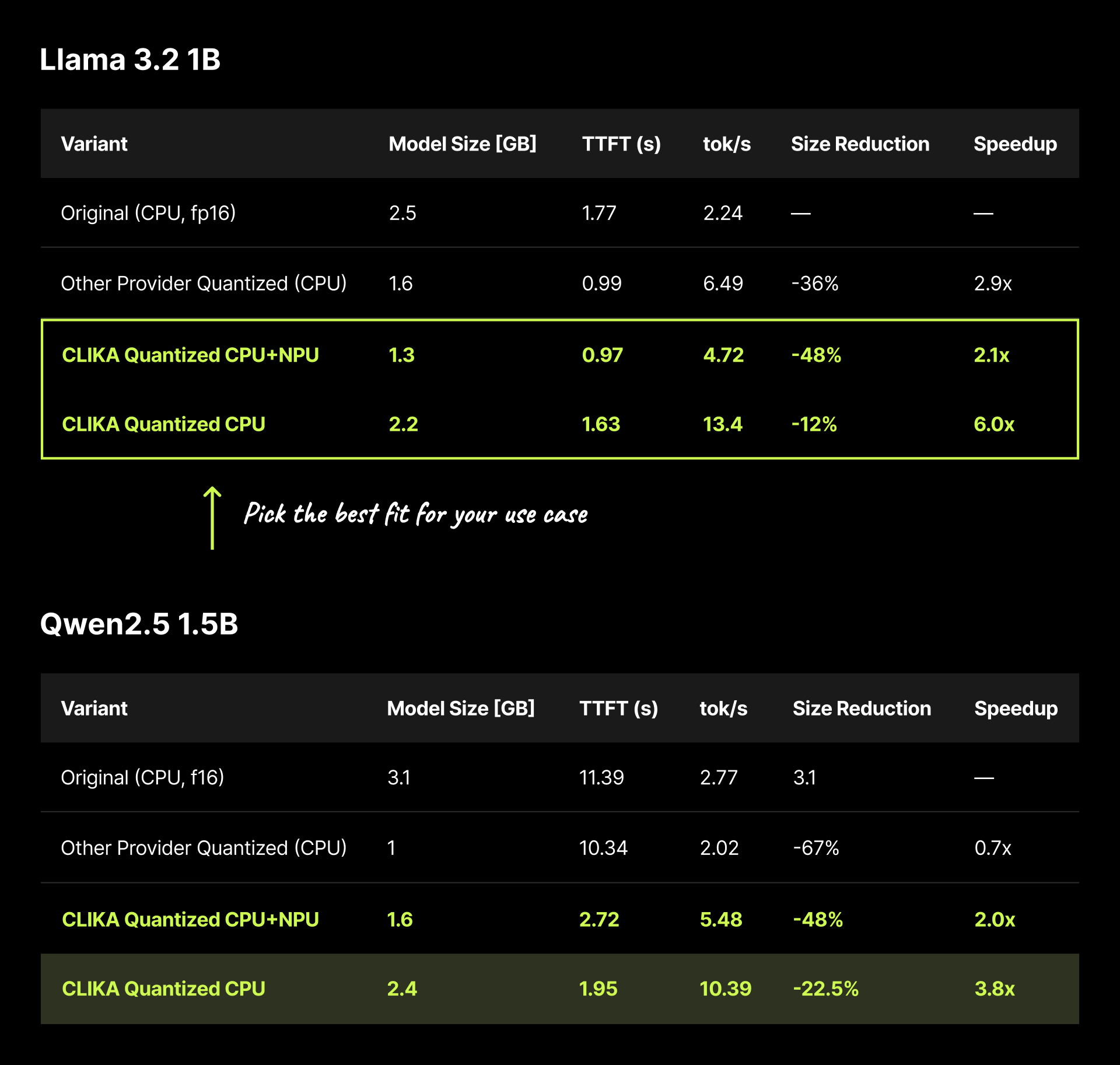
Models below are not available on Qualcomm AI Hub — the largest QCS6490 model on the platform is 110M parameters.
Explore more blogs
.jpg)







